Machine Learning: Email classification
The fundamental rule that Naive Bayes uses: Bayes Theorem
Naive Bayes is a supervised learning classification technique based on Bayes’ Theorem with an assumption of independence among predictors. That is, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. It is a popular technique for text categorization, judging documents as belonging to one category or the other (such as spam or legitimate, sports or politics, etc.) with word frequencies as features.
It tells us how often A happens given that B happens, written P(A/B), when we know how often B happens given that A happens, written P(B/A) , and how likely A and B are on their own.
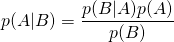
- Here $A$ and $B$ are events and $P(B) \neq 0$
- $P(A/B)$ is a conditional probability: the likelihood of event $A$ occurring given that $B$ is true.
- $P(B/A)$ is also a conditional probability: the likelihood of event $B$ occurring given that $A$ is true.
- $P(A)$ and $P(B)$ are the probabilities of observing $A$ and $B$ independently of each other. This is known as the marginal probability.
Prerequisites
- Install Python
- Install pip
- Install sklearn for python:
pip install scikit-learn - Install numpy:
pip install numpy - Install SciPy:
pip install scipy
Sklearn in Python provides a simple interface to implement popular machine learning algorithms like Naive Bayes.
Training a Naive Bayes model to identify the author of an email or document
In this demo, we use a set of emails or documents that were written by two different individuals. The purpose is to train a Naive Bayes model to be able to predict who wrote a document/email, given the words used in it. The GitHub repo with files is here.
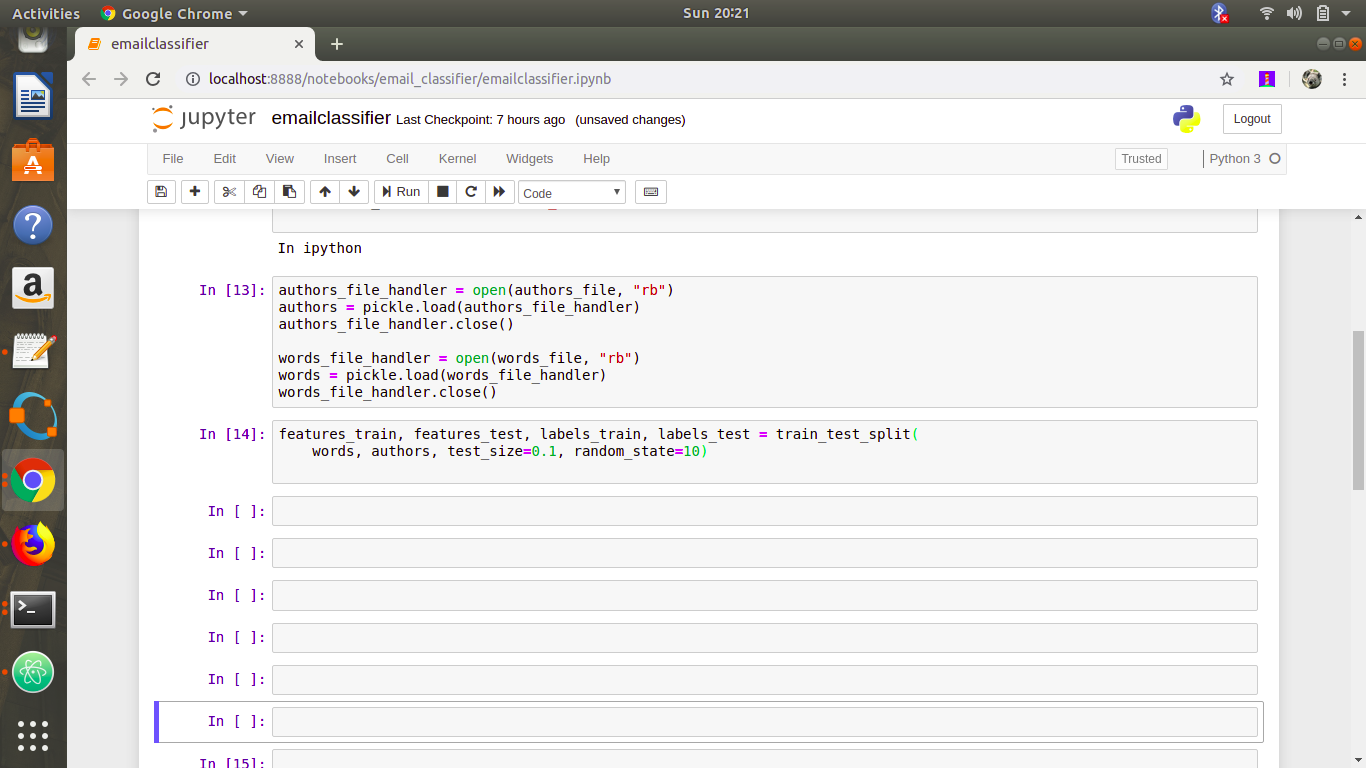
1. Load the data
The first section of the script loads the data.As usual, we split the data into train and test sets using the Scikit-learn method sklearn.model_selection.train_test_split.
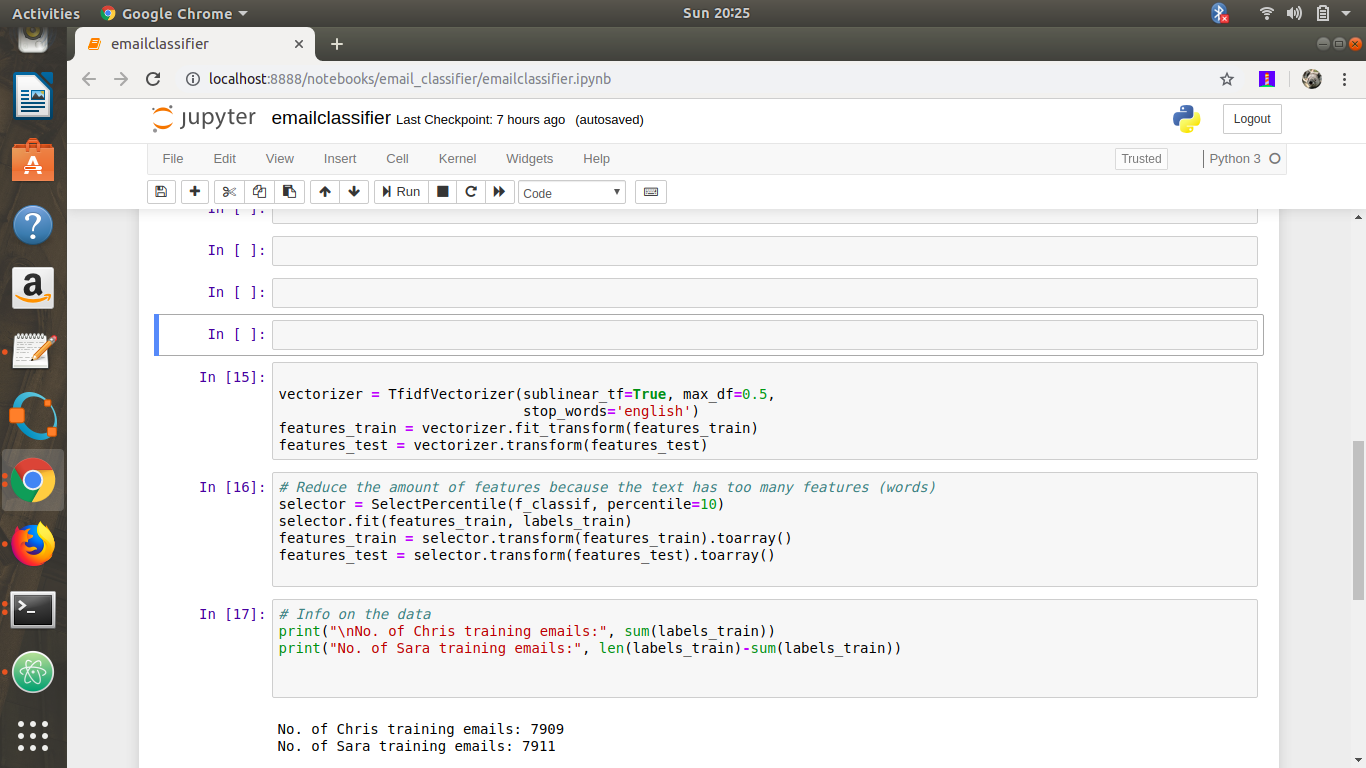
2.Text vectorization
When dealing with texts in machine learning, it is quite common to transform the text into data that can be easily analyzed and quantify.Fortunately for us, Scikit-learn has a method that does just this (sklearn.feature_extraction.text.TfidfVectorizer).
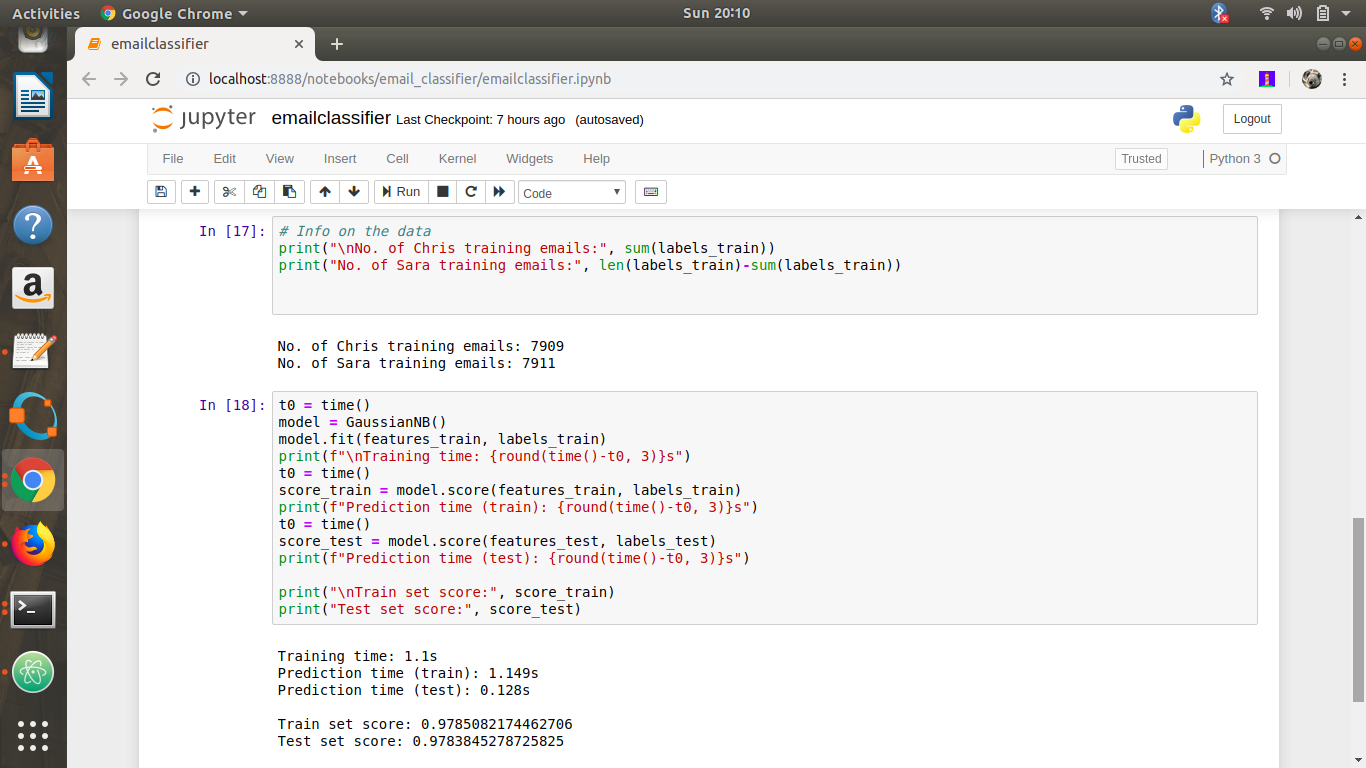
3.Training and predicting with sklearn Naive Bayes
We use a Gaussian Naive Bayes (NB) implementation NB with Scikit-learn
In general, training machine learning models with Scikit-learn is straightforward and it normally follows the same pattern:
- Initialize an instance of the class model
- Fit the train data
- Predict the test data (we omit that here)
- Compute scores for both train and test sets
You can also try
- Other models like Multinomial etc and the accuracy.
- Change frequent words from 3000 to larger and smaller values and find out the accuracy.
